Simplified Transformer Architecture: A Beginner-Friendly Breakdown of How Modern AI Models Work

Attention Is All You Need
In this article, we will break down the Transformer architecture used in large language models (LLMs) like GPT in a simple, visual, and beginner-friendly way. We will explain key components like input embeddings, positional encoding, self-attention, multi-head attention, feed-forward layers, normalization, encoder-decoder stacks, linear layers, softmax, and output embeddings.
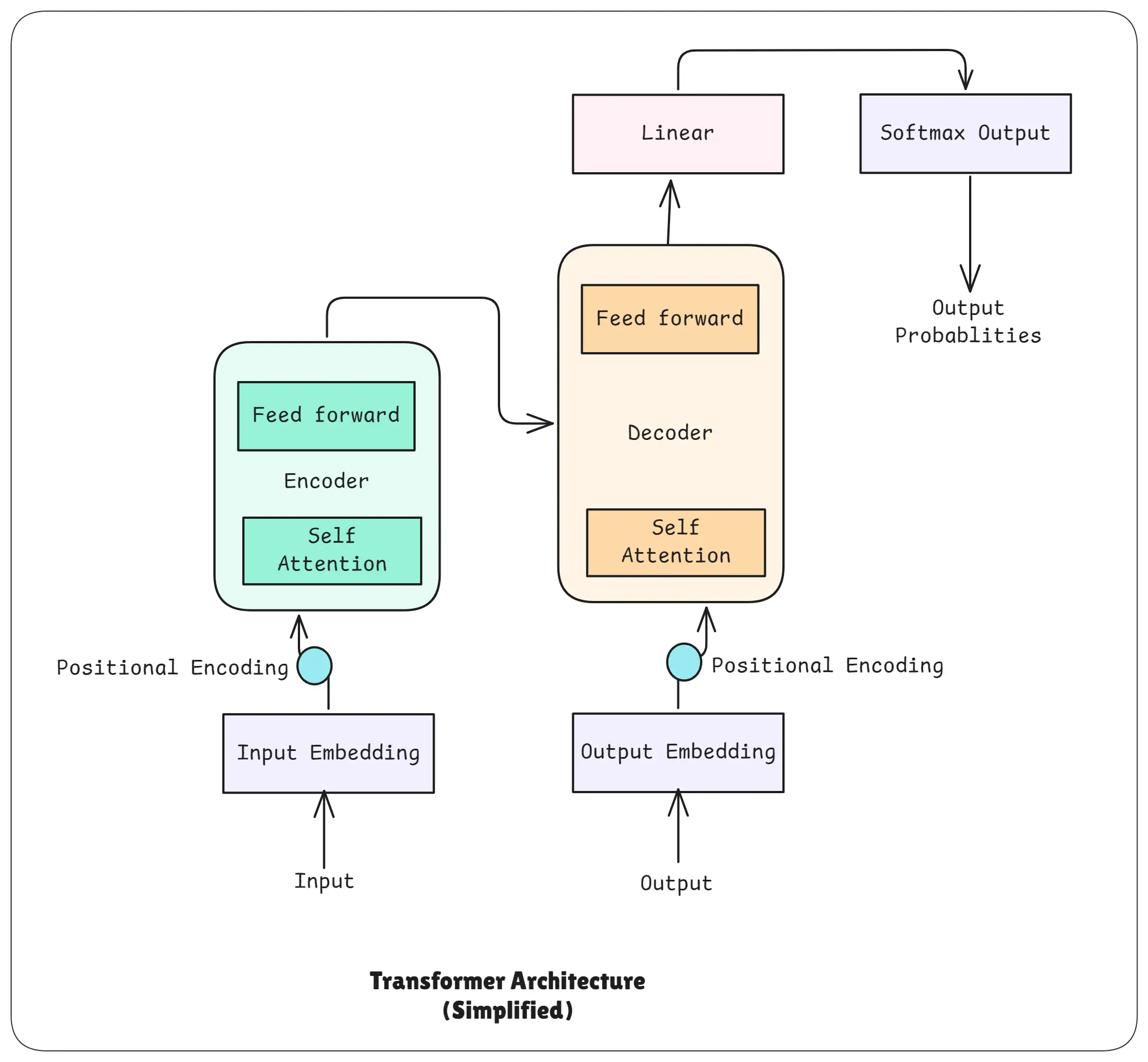
Transformer Architecture
Transformers power modern AI models like GPT, Claude, Gemini, and Llama.
This lesson breaks down the entire architecture in a simple, visual, and beginner-friendly way.
1. What is Input Embedding?
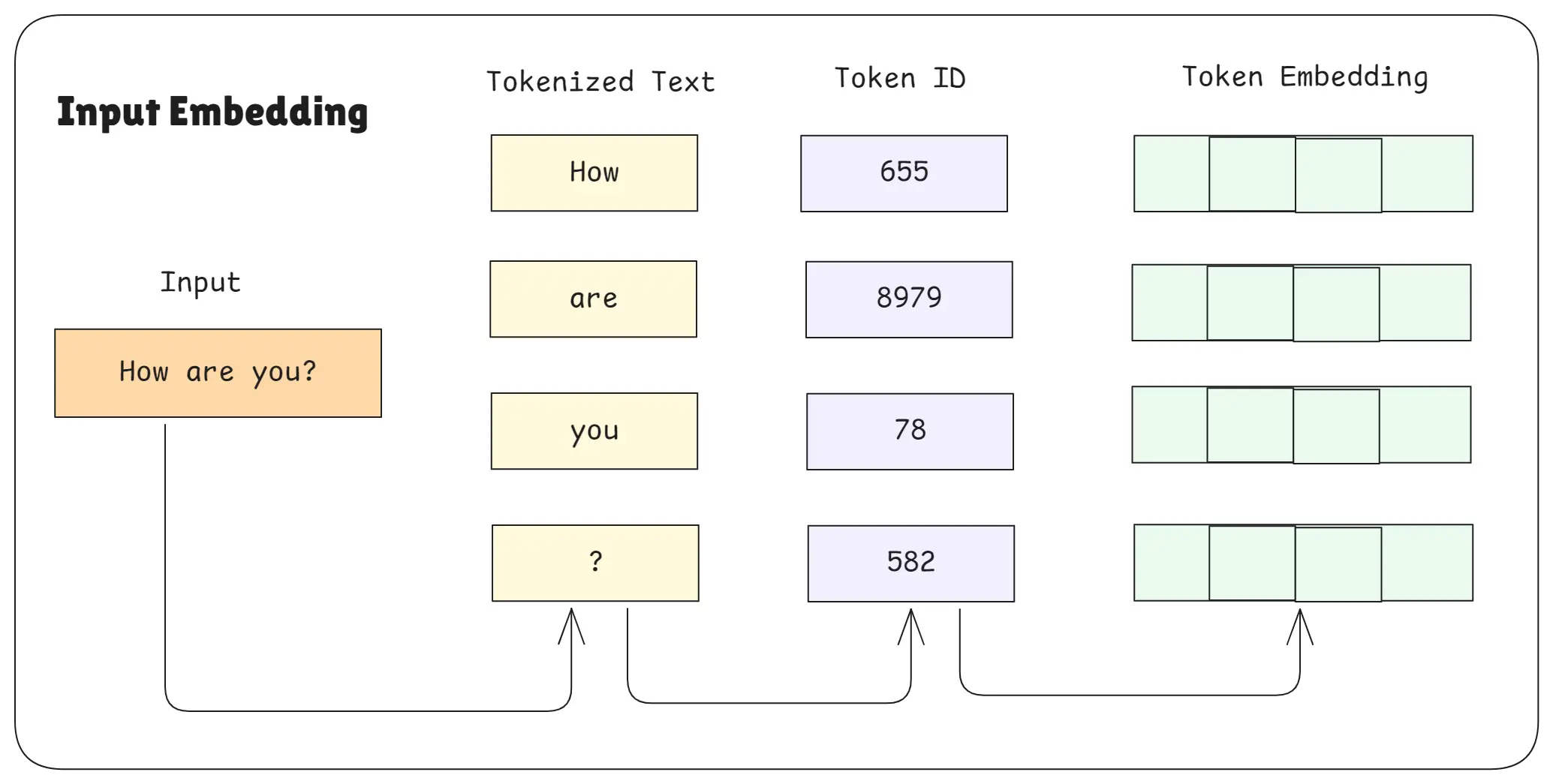
Input Embedding
Input embedding is the process of turning each word/token into a vector (a list of numbers) that represents its meaning. The model cannot understand raw text, so embeddings convert text to numeric meaning.
Simple analogy: Like giving every word a unique “ID card” that contains its meaning and features.
2. What is Positional Encoding?
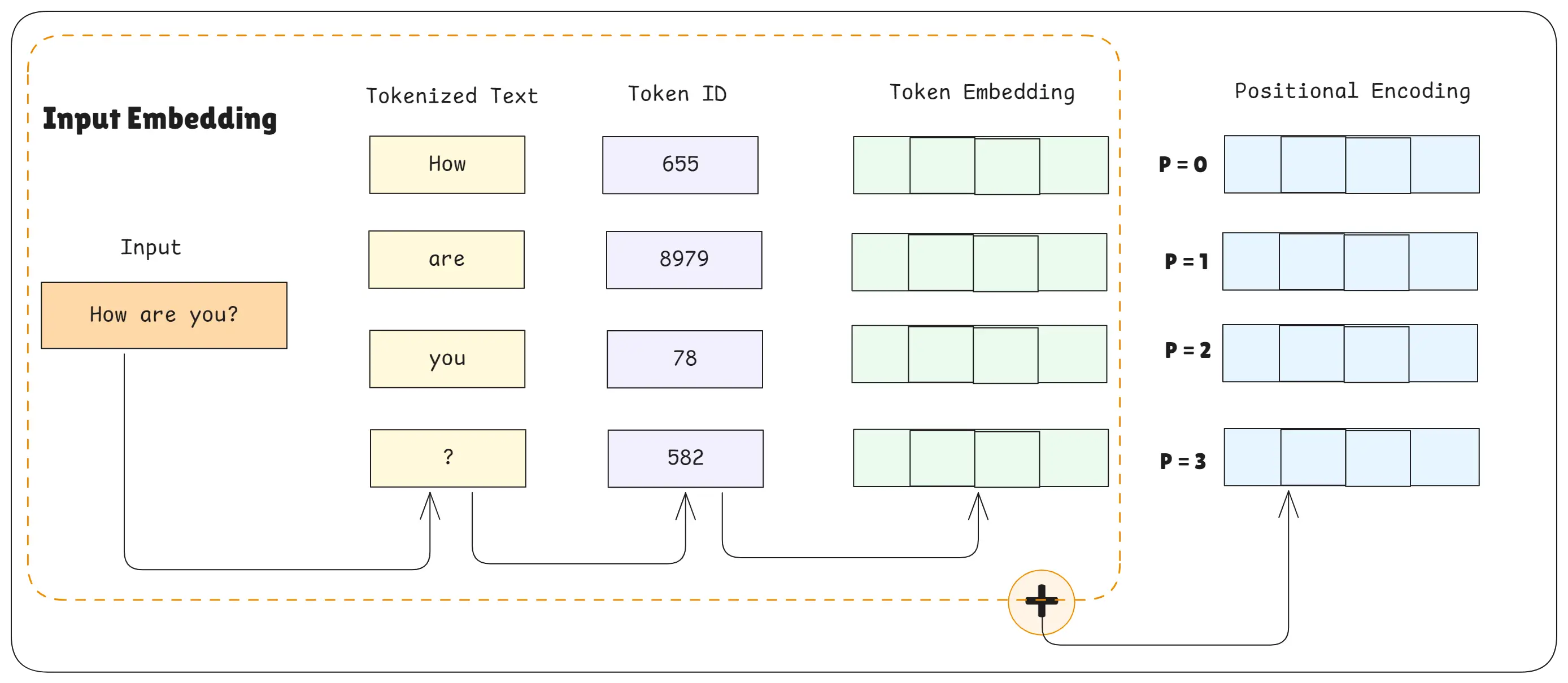
Positional Encoding
Transformers read all words at the same time, so they don’t naturally know the order of words.
Positional encoding adds position information to each word so the model knows which word comes first, second, etc.
Simple analogy: Like adding seat numbers to students so the teacher knows who sits where.
3. What is Self-Attention?
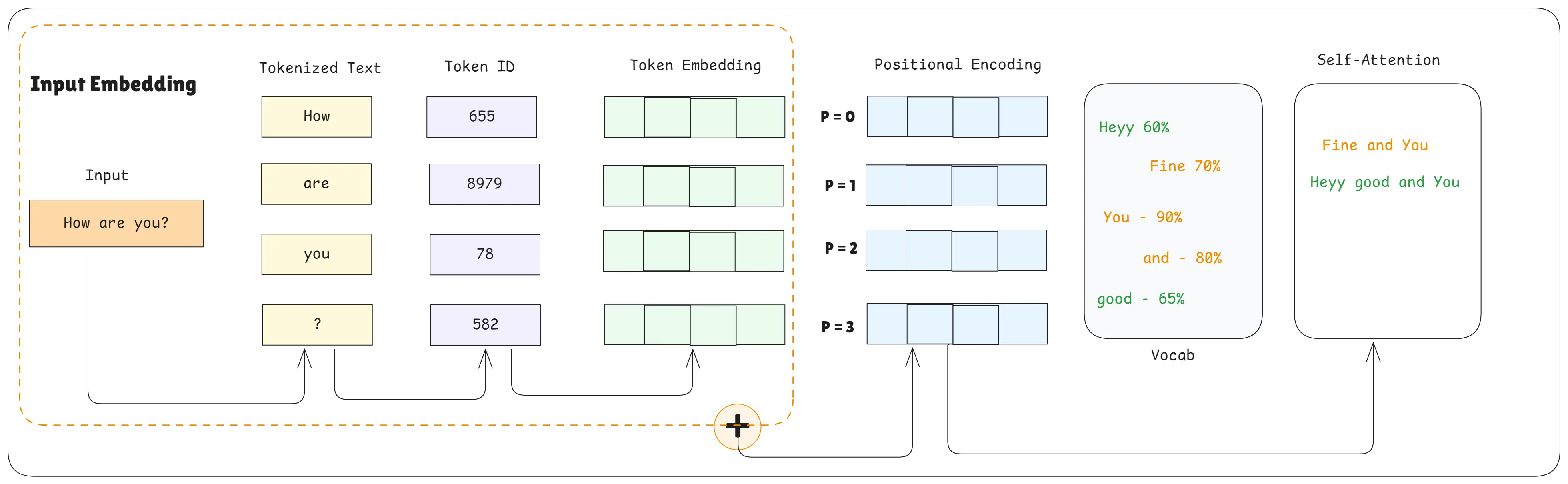
Self Attention
Self-attention helps the model figure out which words are most important to each other.
Each word "looks at" every other word and decides how much attention to give them.
Simple analogy: When reading a sentence, you highlight certain words that help you understand the meaning.
4. What is Multi-Head Attention? (Parallel Thinking)
Instead of using only one attention mechanism, the transformer uses multiple heads to look at the sentence from different angles.
Each head learns something different meaning, grammar, relationships, long-distance links, etc.
Simple analogy: Like having multiple friends giving their opinions, one notices grammar, one notices meaning, one notices tone.
5. What is Feed-Forward Layer?
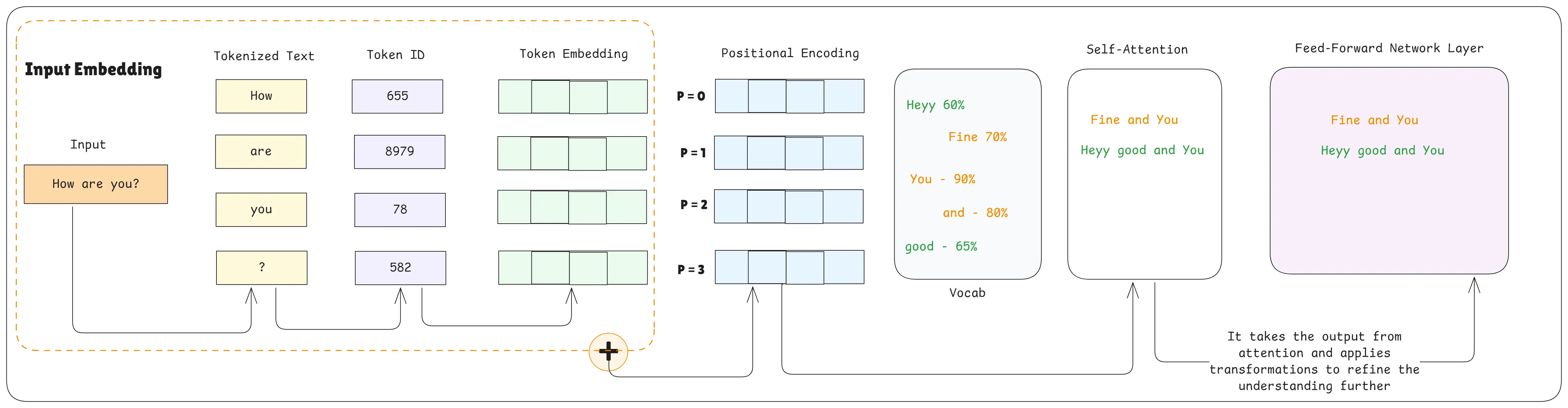
Feed Forward Layer
A feed-forward network layer takes the output from attention and applies transformations to refine the understanding further.
It’s the part that does deeper pattern learning after attention.
Simple analogy: Attention gathers information, feed-forward “thinks” based on that information.
6. What Are Add & Norm?
These are two steps that help stabilize and improve learning. “Add & Norm” means the model:
- Adds the original input (residual connection)
- Normalizes the output so it stays stable
This helps the model learn faster and prevents errors from building up.
Simple analogy: Like checking your work by comparing your original notes to your current draft and keeping everything clean and organized.
7. What Are the Stack of Encoder Layers?
A transformer has multiple encoder layers stacked on top of each other.
Each layer applies attention & feed-forward processing to the input.
Simple idea:
More layers means deeper understanding.
Simple analogy: Like reading a text multiple times, each time noticing deeper details.
8. What Are the Stack of Decoder Layers?
Decoder layers also stack multiple times.
Each layer:
- Uses self-attention on output so far
- Uses encoder output (context)
- Generates the next word step-by-step
Simple analogy: Decoder is like a writer who reads the notes (encoder) and writes one word at a time.
9. What Is Linear (Linear Layer in Transformers)?
A Linear layer (also called a fully connected layer or dense layer) is a small neural network step that turns the model’s hidden understanding into numerical scores for each possible next word.
Simple analogy: Imagine a machine that takes your thoughts and converts them into a list of possible next words with scores.
10. What Is the Softmax Function (Temperature)?
Softmax converts the model’s raw scores into probabilities for each possible next word.
Temperature controls how random or focused the output is:
- Low temp → accurate, predictable
- High temp → creative, random
Simple analogy: Softmax is like choosing the next word based on weighted chances.
11. What Is Output Embedding?
Output embedding turns the decoder’s predicted tokens back into a vector representation for the next step of generation.
It mirrors the input embedding but is used while generating text.
Simple analogy: Like turning each predicted word into a format the model understands for the next prediction.
Conclusion
The transformer architecture consists of:
- Input Embeddings
- Positional Encoding
- Self-Attention
- Multi-Head Attention
- Feed-Forward Networks
- Add & Norm
- Encoder Stack
- Decoder Stack
- Linear Layer
- Softmax
- Output Embeddings
This powerful and efficient design is why transformers dominate modern AI — enabling natural language understanding, generation, reasoning, and multi-modal tasks.
Happy Learning and Building with Transformers!